




1. Observability 란?
: Observability는 시스템 내부 상태를 외부에서 관찰하는 새로운 접근법으로 발생 가능한 근본 원인을 파악하는 관찰자 역할을 수행합니다. 이를 통해 복잡한 분산 시스템에서 문제가 발생했을 때 원인을 빠르게 파악하고 조치할 수 있는 필수적인 개념입니다.
쿠버네티스 환경에서 Observability
•
쿠버네티스는 유동적으로 변화하는 환경으로 파드나 노드나 서비스 등이 지속적으로 생성되거나 삭제됩니다.
◦
이러한 복잡한 분산 시스템 환경에서는 단순한 모니터인으로 문제를 효율적으로 해결하기 어렵습니다.
•
Observability는 시스템의 상태를 더 깊이 이해하고, 다양한 현상의 원인을 파악하고 신속히 해결하는 데 도움을 줍니다.
Monitoring과 Observability의 차이점
•
Monitoring
◦
시스템의 상태를 추적하고 경고를 설정하여 문제 발생을 알리는 역할
◦
사전에 정의된 메트릭 데이터에 의존하여 동작
◦
[What, When] 문제가 무엇이고 언제 발생했는지 초점
•
Observability
◦
시스템 내부 상태를 이해하고 문제의 원인을 파악하는 초점
◦
메트릭, 로그, 트레이스 데이터를 활용해서 동작
◦
[Why, How] 문제가 왜 발생했는지 어떻게 발생했는지 초점
구분 | Monitoring | Observability |
목적 | 문제 감지 | 원인 분석 |
데이터 유형 | 메트릭 | 메트릭, 로그, 트레이스 |
질문 관점 | “문제가 있습니까?” | “왜 문제가 발생했습니까?” |
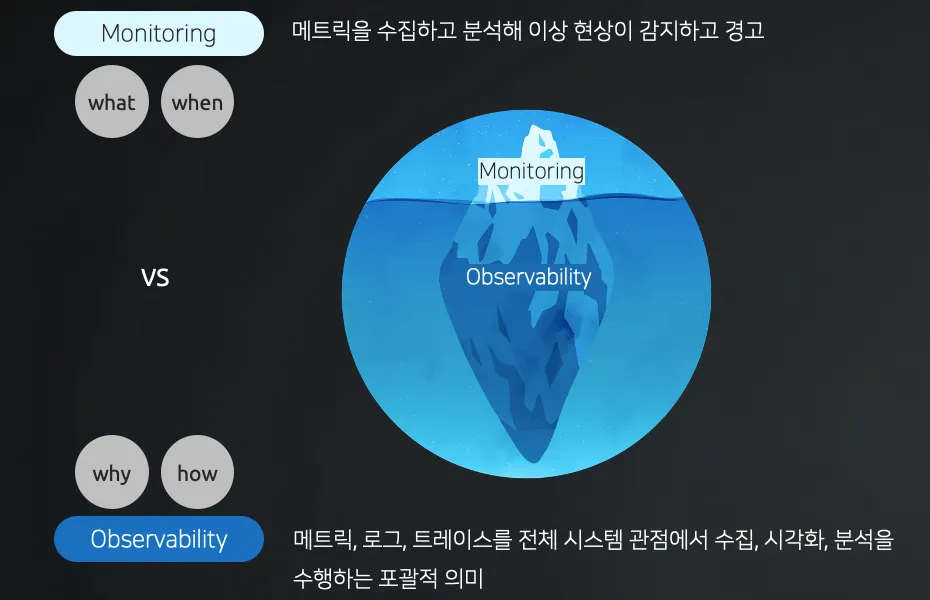
[Caption] Monitoring vs Observability

Monitoring은 전체 시스템을 이해하고 대응하는데 빙산에 일각에 불과합니다.
Observability는 Monitoring를 포함한 큰 범주로 이해할 수 있습니다.
2. Observability 3대 구성 요소
: Observability는 메트릭, 로그, 트레이스 세 가지 데이터 유형으로 구분할 수 있습니다.
메트릭 (Metrics)
•
[정의]
◦
시간 주기에 따라 측정되는 시계열 수치 데이터
◦
시스템 성능 및 상태를 수치화한 데이터
•
[적용 사례]
◦
CPU, 메모리 등의 리소스 사용량 추적
◦
SLA(Service Level Agreement) 준수 확인
로그 (Logs)
•
[정의]
◦
시간 순서에 따라 텍스트로 저장되는 데이터
◦
시스템 프로세스 별로 발생하는 이벤트의 기록
•
[적용 사례]
◦
오류 메시지 확인 및 예외 상황 분석
◦
애플리케이션 동작의 흐름 분석
트레이스 (Traces)
•
[정의]
◦
사용자 요청이 처리될 때 까지 전체 스택을 추적
◦
분산 시스템에서 요청이 각 서비스 간을 이동하는 경로와 시간을 추적
•
[적용 사례]
◦
특정 서비스 호출 간 병목 현상 파악
◦
요청 지연에 따른 포인트 확인
3. Observability 기본 아키텍처
: 큰 그림에서 Observability 구조를 이해할 때 3가지 주요 구성 요소를 분류해서 이해할 수 있습니다.
주요 구성 요소
1.
Collector
•
메트릭, 로그, 트레이스 데이터를 수집하여 Backend System으로 전달
2.
Backend System
•
수집된 메트릭, 로그, 트레이스 데이터를 저장하고 처리하는 역할
3.
Visualization
•
데이터를 시각적으로 표현하여 사용자가 쉽게 이해할 수 있도록 표출
아키텍처 흐름
[Application] → 수집 → [Collector] → 전달 → [Backend System] ← 쿼리 ← [Visualization]
EKS Observability 주요 도구
구분 | Collector | Backend System | Visualization |
메트릭 | Prometheus
Telegraf
OpenTelemetry | Prometheus
Mimir
InfluxDB
VitoriaMetrics | Grafana
Kibana |
로그 | Promtail & Alloy (Loki)
Fluentd
Logstash
OpenTelemetry | Loki
ElasticSearch | Grafana
Kibana |
트레이스 | Jaeger
Zipkin
OpenTelemetry | Tempo
Jaeger
Zipkin | Grafana
Jaeger UI
Zipkin UI |
4. 결론
EKS에서 Observability는 쿠버네티스 클러스터와 애플리케이션의 상태를 효과적으로 파악하고 문제를 해결하기 위한 필수적인 구성 요소입니다.
•
메트릭, 로그, 트레이스를 활용하여 시스템 내부 상태를 깊이 이해할 수 있습니다.
•
위에서 언급한 다양한 도구들을 조합하여 유연한 Observability 아키텍처를 구축할 수 있습니다.